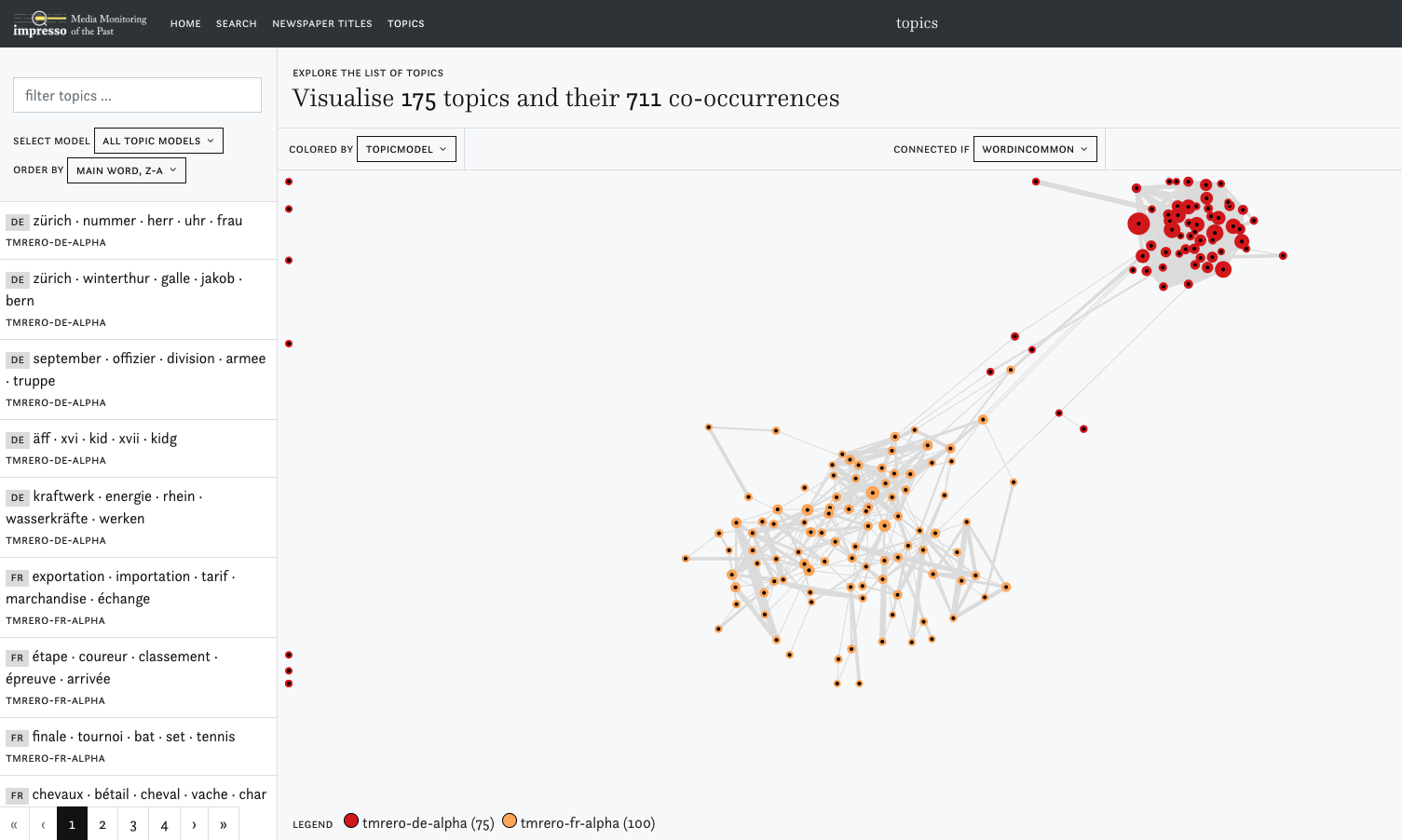
Visualisation of the topics from the French (orange) and German (red) collections
What is a topic model?
Topic modeling is based on the simple assumption that themes are covered by similar words in various texts and that one text can contain several themes. Inverting that assumption, we find that themes can be identified by the words that usually express them. The words a text contains constitute therefore a clue to identify the themes of a text, and are given. Topic modeling helps to discover the word constellation for each document that defines a theme, or a topic, independently of the author or the point of view taken on that topic.
Facing a massive collection of documents, we know the documents and the words they contain. What topic modeling exposes is what the combination of words in each document can tell us from the topics addressed in the documents. To do so, the algorithm starts by attributing randomly a word to a topic and calculates the probability of a topic to appear in a document, based on the words that are randomly attributed to a given topic. At the same time, another probability is calculated: the probability of a given topic to contain certain word, based on the estimated presence of topics in each document, and the word that express them. This is calculated for several iterations, to reach a stronger probability for each word combination that defines a topic and the distribution of the topics across the documents. That means that one article can contain several topics and thus belong to different topics.
For instance: in the press, the word Japan can appear regularly with words such as China, Korea or Asia. Topic modeling, after a few iterations, can propose as a topic the series of words “Japan, China, Korea, Asia, …” and a list of documents, here articles, that are probably linked to that topic, because they contain either “Japan” and “China” and “Asia” or “Asia” and “China” or “Korea” and “Japan”. Not all words need to be present but they are all connected because in the overall of the collection, they tend to appear with one another.
In impresso, topic modeling is applied on a monolingual basis (i.e. considering newspapers of same language). In the topic exploration view, the label of each topic model displays the language, as well as the number of topics.
In this visualisation, topic proximity is based on the number of overlapping words. Hover over the individual nodes to see the most important words of a given topic. Once you click on them, the words will be pinned. You can move around the individual nodes to create clusters.

Manual clustering of topics
On the left pane, you can search topics based on the word they contains, and see the list of all topics. When going on the individual topic page, you will see a list of articles related to that topic.
How were the topics attached to each article?
Newspaper articles of our current collection have been used to “train” the topic models, that means they are the input, the base on which the probability of words appearing together have been calculated. To reach a more relevant result and avoid unnecessary “noise”, some elements have been excluded from the training: short articles and words that are either very common, so-called stopwords (typically the specifiers, such as “le”, “la”, “les” or “der”, “die”, “das”, that give little content information but are very frequent) and the words appearing very seldomly (less than 10 times over millions of articles).
Other steps of the preprocessing include lemmatization, i.e the reduction (normalisation) of inflected word forms to their base forms, “les poubelles” would be normalized to “poubelle”. After that, the articles that contain less than 10 lemmatised nouns were excluded from the training input. This helps remove short texts, especially short advertisements, classified ads. In this particular case, as the focus is more thematic than linguistic, our team proposed to take into account only nouns and ignore other content word classes such as verbs and adjectives that can be interesting for a deeper content analysis but can create some confusion when it is about giving a sense of the thematic content. The goal of all these preparatory steps is to produce an output that is the least ambiguous possible, but we need to keep in mind that certain article types will be excluded from the topics.
As an output of this computing, we obtained on one hand the words that compose the topics and on the other hand the distribution of each topic for each article. This is used in return to attach the articles to several individual topics. This soft clustering, that is a non exclusive linking of an article to a topic, allows us to use the topics as a way to navigate the newspaper collections: in the search page as filters, in the topic page as thematic collection of articles and in the viewer of individual articles, where we can see how many topics have been attached to one article. To avoid cluttering the reading with too much information, we excluded the topics that were estimated to cover less than 0,5% of the article, to keep only significant topics to link the articles.

Topics attached to one article
How to read the topics?
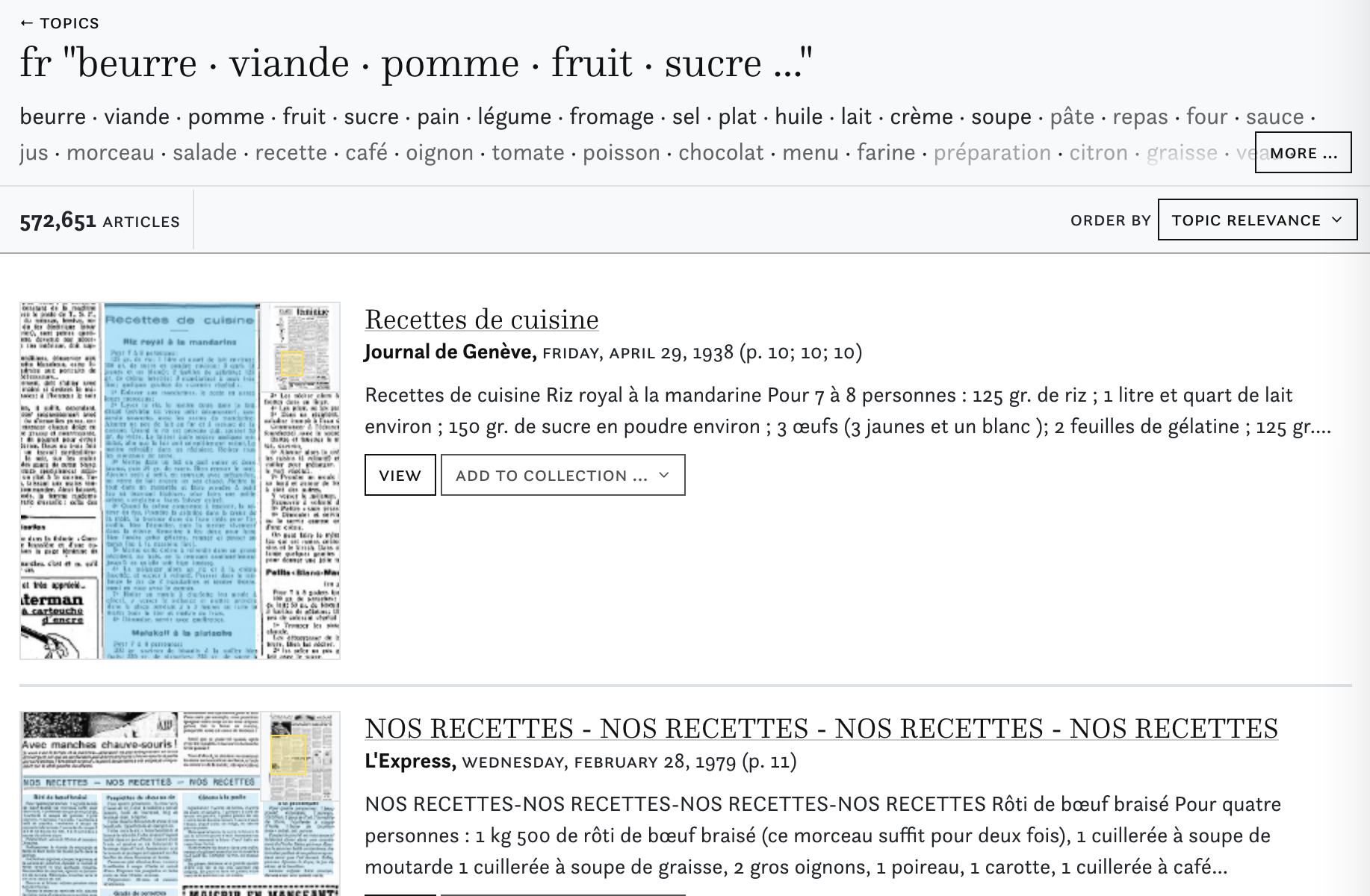
The topic 58, based on the French collections (tmrero-fr-alpha_tp58_fr) collects a series of articles containing some of the words from the following list, that deals mainly with cooking, recipes etc.
fr “beurre · viande · pomme · fruit · sucre …”
beurre · viande · pomme · fruit · sucre · pain · légume · fromage · sel · plat · huile · lait · crème · soupe · pâte · repas · four · sauce · jus · morceau · salade · recette · café · oignon · tomate · poisson · chocolat · menu · farine · préparation · citron · graisse · veau · tranche · filet · poivre · poulet · riz · cuisson · assiette · cuillerée · boîte · goût · porc · verre · aliment · orange · jambon · litre · carotte · thé · conserve · foie · dessert · gâteau · pois · poudre · spécialité · saucisse · ail · bouillon · restaurant · mets · lard · champignon · noix · volaille · oeuf · casserole · confiture · choux · olive · poire · potage · alimentation · mélange · vinaigre · persil · pot · jaune · vitamine · moule · raisin · haricot · paquet · nourriture · poêle · quantité · miel · fraise · saveur · cuillère · cuisinier · glace · tasse · cerise · amande · moitié · biscuit
Topic 58 on gardening and nature
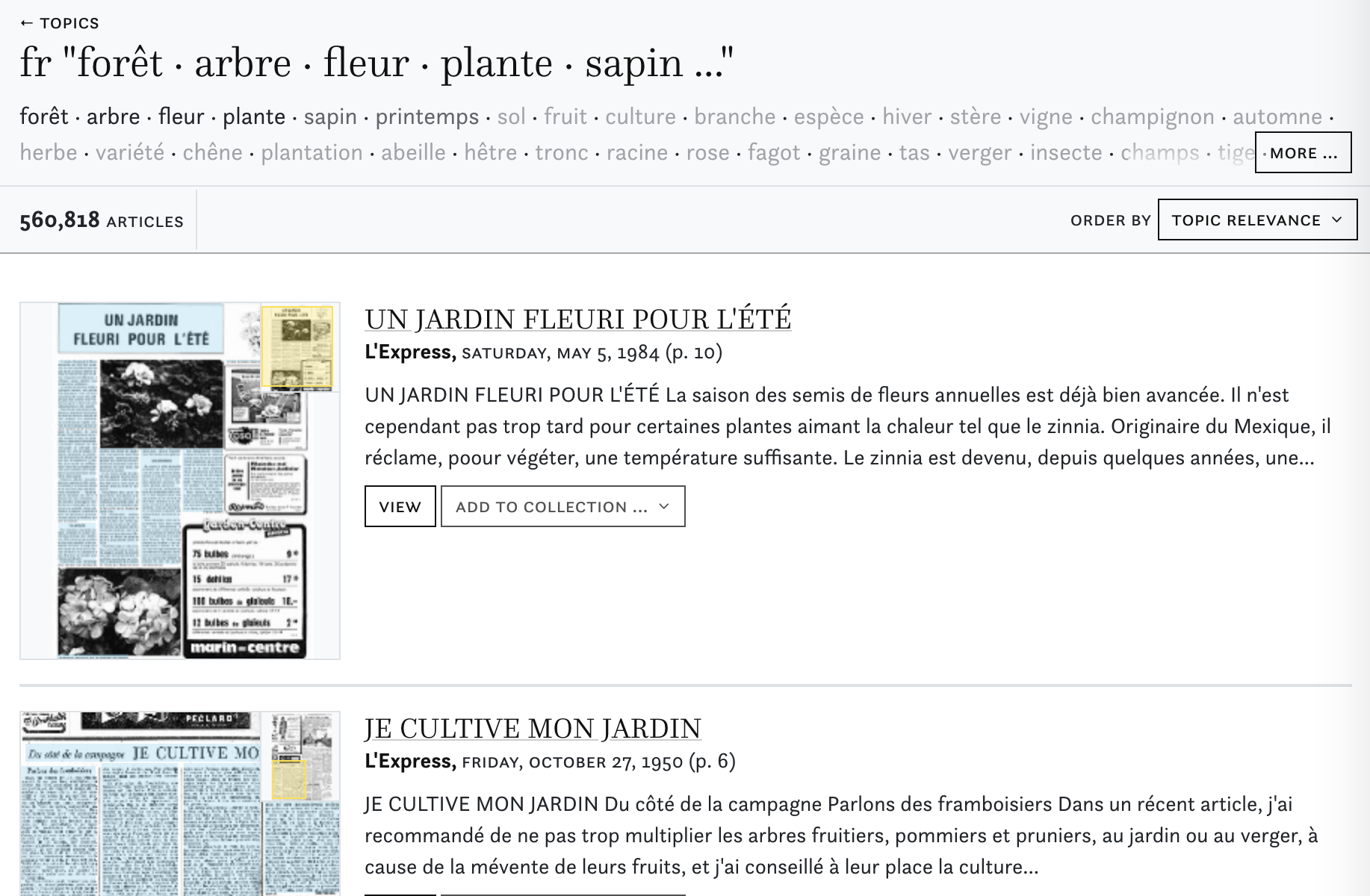
In the topic number 66, also trained on the French language collection, we will find articles containing the words forest, tree, flower, that deals with gardening and nature.
fr “forêt · arbre · fleur · plante · sapin …”
forêt · arbre · fleur · plante · sapin · printemps · sol · fruit · culture · branche · espèce · hiver · stère · vigne · champignon · automne · herbe · variété · chêne · plantation · abeille · hêtre · tronc · racine · rose · fagot · graine · tas · verger · insecte · champs · tige · végétation · jardinier · parc · bouquet · pin · traitement · horticulture · récolte · surface · prairie · centimètre · bûcheron · endroit · hectare · plant · propriétaire · floraison · engrais · pomme · promenade · horticulteur · pré · pâturage · taille · pot · miel · ruche · arbuste · serre · pommier · rendez-vous · quantité · station · parasite · bille · feuillage · tourbe · amateur · billon · propriété · parfum · essence · légume · inspecteur · flore · haie · cueillette · marais · écorce · cerisier · tulipe · forestier · tilleul · rosier · montagne · pluie · gazon · bourgeon · tourbière · couche · rameau · allée · pousse · fumier · climat · grappe · verdure · vignoble
Topic 66 on cooking
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.
A Creative Commons Attribution-NoDerivatives 4.0 (CC BY-ND 4.0) license applies
to all contents published in impresso. While articles published on impresso can
be copied by anyone for noncommercial purposes if proper credit is given,
all materials are published under an open-access license with authors retaining
full and permanent ownership of their work.