Let’s assume a historian wants to investigate the battle of Arnhem and she would like to use newspaper texts for her primary source. She enters her query “Arnhem” into a search engine and finds the two articles you see above. After a quick inspection, the historian deems the first one to be irrelevant for her further research, whereas the second one looks important. If we wanted to assign labels to the two different texts, we would probably choose something like “arts” for the first one, and “war” for the second one. The indicators for these labels are the words that are present in the articles. In the first one we find words like “théatres”, “comédie”, “pièce”, “œuvre”, etc., which we associate with “arts”. In the second one, words like “divisions”, “forces”, “combats”, “troupes”, etc., give the impression of a war-like scenario.
Although we can determine a general topic of a text in most cases, such texts usually are not about one single topic. They rather contain a mixture of topics. We also find other words in the first text, e.g., “suisse” or “Zurich”, which helps us to put this article in a Swiss context, meaning if we were looking for Swiss artwork (instead of Arnhem), this article should pop up in our search. Names, like the one of the Swiss author "Friedrich Dürrenmatt", enforce this context. This is why named entity recognition (NER) helps us to further contextualise the information we find in the text.
Upon closer inspection, we not only notice words that are characteristic for a specific article, but we also stumble upon words the two articles share. But not every word is of equal importance. Prepositions and articles, like “en” or “la” do not play a role in assigning topics to texts. Words like “Vienne” or “théatres”, on the other hand, matter. As such, we can say that a text tends to contain several topics, while each topic consists of several, ideally semantically coherent words. In our first text, the topic “arts” would dominate, since most of the words can be found in the art context. The second text, however, would be dominated by the “war” topic, but the topic “arts” would probably be represented as well, since the word “théatres” occurs once (even if it is used in a different context). So the topic distribution could look something like 90% topic “war”, 5% topic “arts”, and 5% some other topic. Hence, we are able to sort texts according to their topic distribution, which allows to refine search hits by not only excluding articles (like in the example above), but also extending the search in order to find articles on similar topics (maybe the researcher would find reports about the battle of Dunkirk if she wanted find articles with a similar topic distribution as the one from above).
In topic modeling, we try to find out first which words belong to which topic, where one word can occur in several topics. As training data we take all our newspaper issues. Before training a topic model, we have to define how many topics we want to find in our corpus. This choice has a big influence on the outcome. If the number of topics is too low, the topics will be too general and mixed, whereas a too high number will result in too specific topics, most of which won’t be of much use for grouping documents.
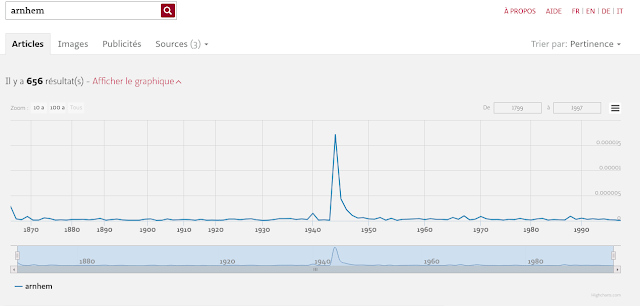 |
| Frequency distribution of the query term "arnhem". |
In a second step, by applying topic modeling on articles, we are able to perform so-called soft clustering, which aims at classifying texts according to their topic distribution. In the impresso project topic models will help to identify pages or articles (only for newspapers for which we have article segmentation) with a similar topic distribution. When we look for “Arnhem” in the archives of Le Temps (as shown in the two images above), we find texts about the battle, but also about other events that happened in Arnhem (like sports results, art exhibitions, industrial news, etc.). What’s more, if we use the German spelling, namely “Arnheim”, we find 178 more hits (although it seems the spellings belong to different time periods, as you can see below). If we want to filter out the articles about sports, etc., and if we want to include the articles in which the other spelling variant is used, we can use a topic model to find related articles, namely those which are about war, and not sports or art events. And since we focus on finding similar articles based on the topic distribution, we don’t even need to start a new search with “Arnheim”, since we assume that the topic distribution of all articles which are about the battle of Arnhem should be comparable. Or, alternatively, we use the keywords and/or named entities the articles about Arnhem contain and filter (or extend) our search according to those keywords.
 |
| "arnheim" vs. "arnhem". |
Now imagine you want to find out how different newspapers reported about the battle of Arnhem. It could well be that the political orientation of the newspaper (or the one of the author, or the chief editor, or the publisher) has an influence on what information you find in the text (or what is missing). Thus, you would like to find all articles about the battle of Arnhem. Since Switzerland is a multilingual country and the impresso collection contains French and German documents (while we also think about including other languages), one desideratum would be to find similar texts across language boundaries. This is where cross-lingual topic modeling comes in. With parallel texts, meaning translated text, cross-lingual topic modeling is not a big deal and has already been explored by some researchers.
 |
| Similarities across newspapers. |
|
The challenge we face when working with newspapers is that, e.g., the Journal de Genève (JDG) of 15.06.1944 is not a translation of the Neue Zürcher Zeitung (NZZ) of the same day. However, we might find similar topics. As we can see, the main stories are not the same. The NZZ focuses on the battle in the Normandy, while the title story of the JDG is about an ongoing battle in Russia. The overall main topic, though, would nevertheless be related to war. Although the lead articles do not report about the same incidents, we nevertheless find similarities across the page. First of all, we find very closely related images, the one of the NZZ showing Bernard Montgomery, who served as Winston Churchill’s Field Marshal from 1944 onwards. The second shows Churchill himself. Both, Montgomery and Churchill, are visiting the troops in the Normandy. But we also find textual similarity. The green framed passages indicate texts which are about the Normandy, while the light blue frames highlight snippets about Montgomery. Our aim in impresso is now to find a way how we could identify such similarities across languages, thus providing researchers with more, and hopefully also more relevant, material.
Working with digitised newspapers poses yet another challenge. The quality of the digitised content depends on how careful the digitisation process was carried out and what models were used for the Optical Character Recognition (OCR). The images we have received are not always of high quality and this has severe implications on the quality of the OCR. This not only means that we have to find methods to correct these OCR errors, but also that we are somehow forced to apply our text mining methods on “dirty data”. In order to show the degree of “harm” using dirty data for topic modeling, we tried to extract 50 topics from the NZZ (we've only used 60'000 pages) with MALLET. In the following table, you find three topics out of these 50 which are semantically coherent:
1
|
kunst konzert bild theater künstler oper musikalisch spielen werk künstlerisch orchester aufführung ausstellung lied musik vortrag stück chor musil programm
|
2
|
deutschen britisch deutsch truppe krieg russisch angriff flugzeug feindlich schwer front armee kampf london japanisch havas amerikanisch feind alliiert italienisch
|
3
|
zimmer lage vermieten verkaufen wohnung garten groß auskunft villa hotel schön zürich haus pension komfort preis see telephon sonnig modern
|
The first one refers to the arts, while the second one can be associated with WWII. In the third topic we find words which are most often used in the context on flat advertisement. However, there are also topics which suffer from the poor OCR quality of the NZZ, as we show in the next table:
4
|
vita dtt chm dje dew dep ftn stm dtn mem hät ftm bch dim dtr ßch mam vow pie stch
|
5
|
unc clie icl ncl iic ssc unci icr clen vnn clc cll lcl icli unss llc nci clic ncn nnc
|
6
|
nicken bitten vnn icl eit lill nicbt gen liegen clcr clie klein cit bereit cke eilen cin lum immer ckcn
|
7
|
bass werben wild leinen iahen mehl enn übel wal fehlen non tann fühlen zul nui zui übn hatt ihi wied
|
We see that the majority of words in each of these four topics consists of OCR errors. In total, 13 out of 50 topics look like the examples in 4 - 7. This is a serious flaw and we need to tackle this problem with either a re-digitisation of NZZ material , or a re-OCRing of the scanned images, or both.
Applying text mining to data from which we do not know how clean it really is quickly reveal the most common errors. For this reason, cleaning up as much as possible is vital for the continuous and manifold work that is currently done on digitised texts. Only after having established a clean basis we can continue with our work and think about how we can model topics across languages, and also, how to evaluate them. These are some unanswered and lesser researched questions I'm turning to next.