Impresso 2 in a nutshell
The first Impresso project (2017-2020) compiled and semantically enriched a corpus of digitised Swiss and Luxembourg newspapers and designed a system architecture and user interface, which together form the Impresso app.
Impresso 2 continues these efforts and proposes to overcome language and media barriers and, for the first time, to enable joint exploration of newspaper and radio archive content across time, language and national borders. Leveraging an unprecedented corpus of transnational print and broadcast media, this second project aims to enrich and connect these sources into a common vector space, and to design appropriate, meaningful and transparent exploration graphical and API-based interfaces for historical research from a transmedia and transnational perspective. These efforts will be guided by original research on historical media ecosystems, which will explore these newly available data from the perspectives of (media) history and by using data-driven research methods.
We are honoured and excited to collaborate with Western European (old and new) partners, and thank the Swiss National Science Foundation (SNSF Sinergia grant 213585) and the Luxembourgish Fond National de la Recherche (FNR, INTER 17498891) for their continued trust.
Since the official launch of the project in September 2023, we have been busy preparing the contractual foundations of the project, setting up data collection from our partners and, most importantly, assembling the new team.
We are also pleased to announce a new project homepage, a new component for exploring text reuse data, as well as other updates to the Impresso web app. Have a look!
New project home page
Screenshot of the redesigned Impresso home page
We are pleased to announce a completely redesigned project homepage which informs you of the Impresso 2 research objectives in natural language processing, history and design.
Impresso Text reuse at Scale
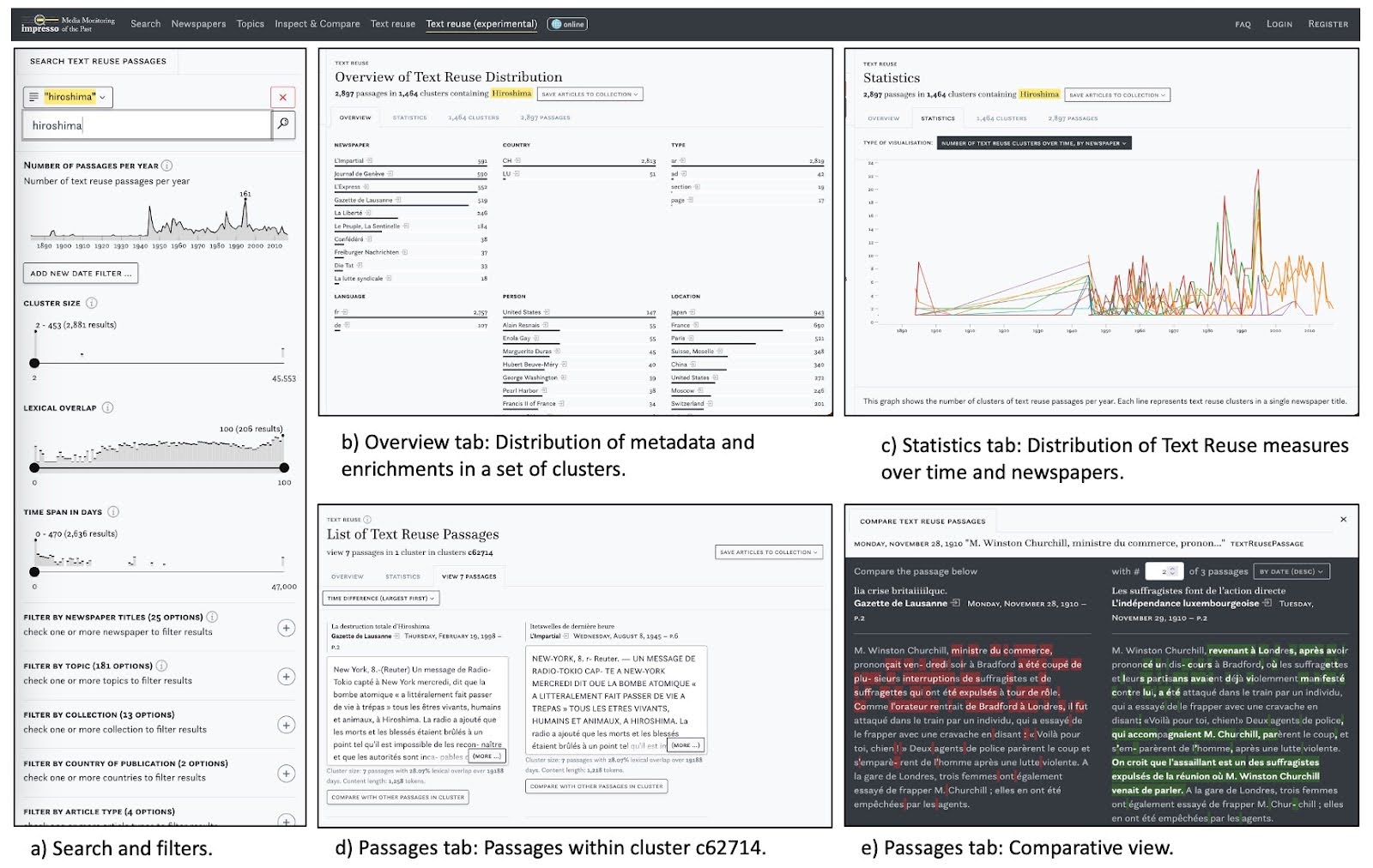
The main components of Text Reuse at Scale application, Search and Filter Pane (left) and Overview, Statistics and Passages tabs (centre)
Text reuse detection counts among the most popular techniques for computational enrichment of historical newspapers and publications more generally and has been applied successfully by research groups around the world. In November 2022 we organised a small workshop with experts in text reuse detection, NLP, history and design to revisit the previous Impresso text reuse explorer. Specifically we wanted to find out how the integration of text reuse with other forms of semantic enrichment such as content type detection and topic modelling could advance the study of historical text reuse.
Based on research objectives, tasks and mockups developed during the workshop, we are happy to announce the launch of an all new text reuse component for the Impresso web app: “Text Reuse at Scale”.
The new component allows you to formulate precise queries based on all filters available within the web app and to shift between a close-reading comparison of two text reuse passages to high-level overviews of the distribution of text reuse clusters across our corpus.
Try it out
If you would like to know more about our work with Text Reuse, take a look at these publications:
-
Düring, Marten, Matteo Romanello, Maud Ehrmann, Kaspar Beelen, Daniele Guido, Brecht Deseure, Estelle Bunout, Jana Keck, and Petros Apostolopoulos. “Impresso Text Reuse at Scale. An Interface for the Exploration of Text Reuse Data in Semantically Enriched Historical Newspapers.” Frontiers in Big Data 6 (2023). https://www.frontiersin.org/articles/10.3389/fdata.2023.1249469.
-
Romanello, Matteo, and Simon Hengchen. “Detecting Text Reuse with Passim.” The Programming Historian, 2020. https://doi.org/10.46430/phen0092.
-
Romanello, Matteo. “Text Re-Use Detection in a Nutshell.” Blogpost. impresso, June 12, 2018. https://impresso-project.ch/news/2018/06/12/tradingzone-tr.html.
The Impresso widget allows you to embed public domain Impresso content as iframes outside the web app.
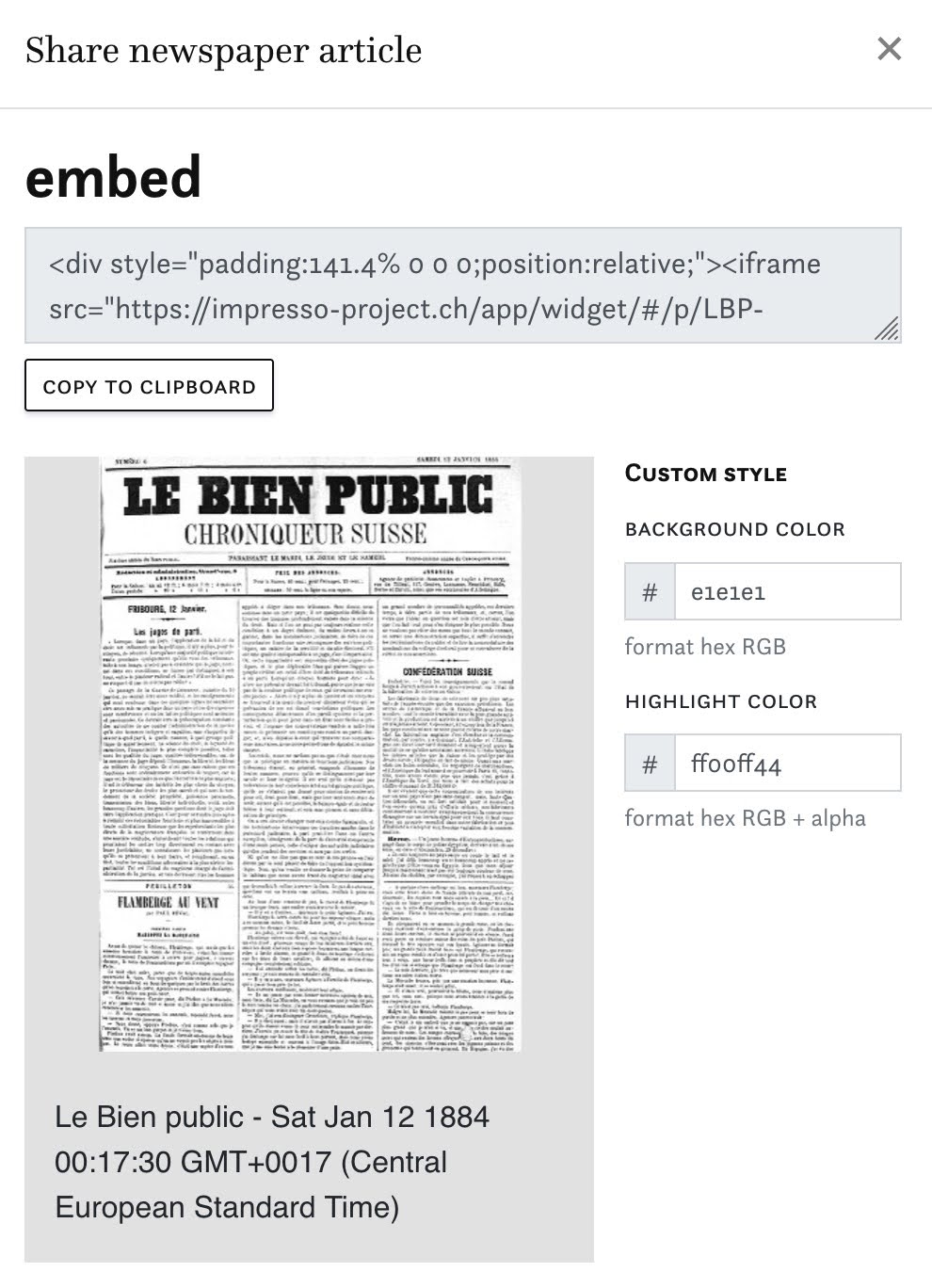
Impresso widget
In discussions with journalists, the idea emerged to allow authors to include Impresso content in publications. A classic example is press articles that refer to events in the past. Rather than simply providing a screenshot of a historical newspaper article, we wanted to give journalists the ability to embed the article in an iframe, allowing readers to not only read the article itself, but also to access additional context via links to the page and the the entire issue. For copyright reasons, this feature is currently limited to public domain material.
Where to meet the Impresso team
We are happy to hear from you, so please do not hesitate to contact us with any feedback or ideas you have for Impresso. You can always reach us at info@impresso-project.ch, via the Impresso user Slack group and at the following events - based on what we have confirmed at this stage:
DhD - Digital Humanities im deutschsprachigen Raum 2024
Marten Düring offers a workshop titled “Machine Learning to Read Yesterday’s News. How semantic enrichments enhance the study of digitised historical newspapers”
Planned for the 27th February from 9-12.30 in room WiWi SR 027.
Invited talk on Impresso at LaTeCH-CLfL 2024
Maud Ehrmann and Marten Düring will give an invited talk on Impresso at the 8th Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature (LaTeCH-CLfL 2024) collocated with the EACL 2024 conference on March 22nd in Malta.
At the same workshop, Emanuela Boros will present an exploratory study on historical transcript post-correction with a large language model.
Please find the corresponding paper here:
Emanuela Boros, Maud Ehrmann, Matteo Romanello, Sven Najem-Meyer, and Frédéric Kaplan, eds. “Post-Correction of Historical Text Transcripts with Large Language Models: An Exploratory Study.” In LaTeCH-CLfL 2024, 133–59. The Association for Computational Linguistics, 2024.
Participation to a track at AMLD 2024
Maud Ehrmann will participate in a panel on “Natural language processing for GLAM collections” at the Applied Machine Learning Days on March 25th in Lausanne.
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.
A Creative Commons Attribution-NoDerivatives 4.0 (CC BY-ND 4.0) license applies
to all contents published in impresso. While articles published on impresso can
be copied by anyone for noncommercial purposes if proper credit is given,
all materials are published under an open-access license with authors retaining
full and permanent ownership of their work.